
Plagiarism- the bane of any content and a major blemish in any person’s reputation caught participating in such an act. The concept of plagiarism is closely associated with the idea of integrity. While most unintentional plagiarism cases have harmless reasons, every intentional or blatant plagiarist has some deeper motive in mind and money is the most common one. Nevertheless, no matter what kind we encounter, plagiarism is an offense in every conceivable sector, whether it is education, commercial, or non-commercial.
Artificial Intelligence and Machine Learning are offeringsome astounding breakthroughs. Whether text, image or any other kind of data, AI models are now being used extensively in the field of plagiarism detection. Numerous online plagiarism checker tools are now widely available online with powerful AI models running in the background. These utilities cannot only compare a text with millions of references in an instant but deliver results with unerring accuracy.
This article looks into the inner workings of AI-powered plagiarism detecting software that identify textual plagiarism with incredible speed & accuracy.
Natural Language Processing
Now, with the plethora of content and information spread across the digital & physical realm, detecting plagiarism is becoming increasingly challenging. It is the era of Big Data, and manual plagiarism detection is no longer a possibility. The marvels of computer science and programming come to the rescue as we now have different plagiarism detection methods that can scan & identify collusive content at breakneck speeds. Yet again, the sheer amount of content is one of the most significant constraints and handicaps of conventional plagiarism detecting methods.
Commonly used plagiarism and collusion detecting mechanisms use iterative measures to compare words (strings) in a text. Given the massive amount of content available online, this technique is impractical from every conceivable angle.
The recent unprecedented boom in artificial intelligence has brought forth an array of groundbreaking data analysis techniques, which are efficient, effective and require minimal to zero human intervention.
- Machine learning is a branch of AI that involves training AI models to perform tasks without any human intervention and designing models capable of outperforming conventional/non-AI data processing techniques.
- Natural Language Processing is a multidisciplinary field involving machine learning and computational linguistics, aiming to train AI -capable models to understand & process natural human language.
- NLP models are not just capable of detecting duplicate words, but determine similar words or synonyms, matching structure and even the narrative & the context of any written content
Just like any other computational model, NLP, too, processes any text as raw data and employs critical mathematical & statistical analyses to identify any duplicity with impunity. There is even a rich suite of libraries for symbolic & statistical NLP called the Natural Language Tool Kit (NLTK) written in and for one of the most famous & powerful languages used in AI, Python.
AI engineers and software developers are using Python, the NLTK and NLP modelling to devise unique & accurate ways of detecting textual plagiarism.
Textual Plagiarism Detection Techniques
The process of textual plagiarism detection defines two essential formal tasks, intrinsic and extrinsic detection. While extrinsic plagiarism detection has an external corpus acting as a reference, intrinsic detections occur without any external comparison. Similarly, the extent of obfuscation varies from one text to another. Some may exhibit unintentionalor minimal plagiarism while others may be verbatim copies of some text.
Some of the most common textual plagiarism detection techniques used in NLP are:
- Syntax based detection
- Semantics-based detection
- Cross language-based methods
- Citation based models
- Vector Space Model-based models
Each of the above detection methods falls under the corpus of NLP and is just different ways machine learning models are taught to process human language.
A Typical NLP Pipeline Source: www.copyleaks.com
Machine Learning Algorithms for NLP
- k-nearest neighbors or k-NN is one of the simplest machine learning algorithms in machine learning used widely in pattern recognition & plagiarism detection. Recognizing patterns is a crucial aspect of plagiarism detection, and the k-NN algorithm does it with the utmost efficiency.
Without going into excessive technical details, we can say that the k-NN algorithm classifies and categorizes text.
- It classifies a set of training data or text and collects information about important words & their possible distributions in that category. It determines the similarity between different documents and categorizes the most similar ones.
- The features that determine or act as a metric of similarity between documents can range from Euclidean distance or the cosine similarity between two word vectors.
- If k=3, then the document’s features under test are compared with three texts in the training corpus with the closest similarity with the test document.
- Semantic similarity measurement between two documents using NLP is another technique used to determine similarity. The method involves building a repository containing both reference corpus and the input document. NLP techniques are then used to determine the semantic similarity between the texts under comparison.
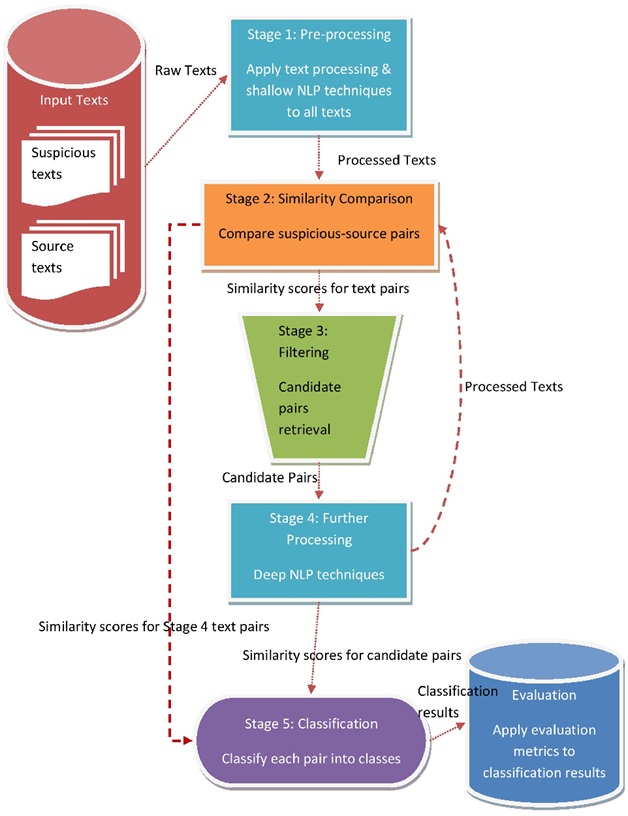
The process is quite technical, but here’s a quick rundown of the NLP pipeline.
- After creating a data repository made up of both references & the input text, the input text undergoes preprocessing. Text is considered as a type of unstructured data. Preprocessing helps clean data, remove noise, highlight prominent & useful features, carry out tokenization & lemmatization,etc.
- Next up, machine-learning models use NLP techniques to determine the semantic similarity between two documents and obtain various similarity scores. The Naïve Bayes Classifier is a popular probability measurement technique used by machine learning-powered plagiarism detection methods to determine the similarity index.
- Miscellaneous Detection Methods
String Similarity Metric is a commonly used extrinsic plagiarism detection algorithm. It uses the Hamming Distance technique to detect the number of different characters between two strings of similar length and the Levenshtein Distance that analyses the minimum editing required to convert one string into another.
The Vector Similarity Metricis used to check the similarity between two different texts. Various vector detection techniques such as Matching Coefficient, Dice Coefficient and Overlap Coefficient are the underlying concepts used in machine learning programs. Vector detection focuses on the text’s stylistic features rather than its linguistic features.
There are several other ML techniques used to determine & detect measures of similarity between two texts. Here’s a list of the most common ones.
- Character-Based Methods
- Vector-Based Methods
- Syntax-Based Methods
- Semantics-Based Methods
- Stylometric-Based Methods
Before wrapping up, let us quickly look at a simple machine learning plagiarism detection process used by most plagiarism checker tools online.
A brief glimpse of the detection process
Here’s a glimpse of one of the most straightforward NLP powered plagiarism detection processes.
- The software scans a passage and takes note of the stylistic similarities and word choices.
- The AI notes critical words and sentence clauses. Most ML-powered plagiarism detectors stem words to reduce complexity, such as ‘fishing’, ‘fishers’, etc.
- Tokenization, lemmatization, dependency parsing, parts-of-speech tagging, sentiment & context analysis, etc. are the next in the NLP pipeline. Sentence identifiers are compared with their synonyms and translations.
- Similarity detection measures are then used to determine the level of collusion between two texts.
And, that’s all the space we have for today. Hope this write-up offered you an informative glimpse of the machinations behind most online plagiarism detection methods